
数据传输是将信息源产生的数据迁徙到数据处理平台的过程,这个过程的主要需要考虑两个因素:一是传输系统的性能,既不能影响信息源系统的正常运行,也要考虑分布式数据计算平台的处理能力。二是数据传输的安全,在传输过程中,不能造成数据的损失,因此要保证传输的可靠性和稳定性。
1.1 研究背景
大数据:通常定义为数据量特别大、数据结构相对复杂,且无法用传统的技术进行存储、管理和处理的数据集;其主要特点被称为4V:数据量大(Volume)、数据类别复杂(Variety)、数据处理速度快(Velocity)和数据真实性高(Veracity)[2] 。大数据技术是以Google于2003年到2004年间发表的MapReduce、 GFS(Google File System)和BigTable三篇分布式计算理论技术论文为起点的,其中MapReduce是一套针对分布式并行计算的编程模型,是分布式计算的框架;GFS是分布式文件系统适用于对大型的、大量数据的分布式管理应用;BigTable是基于GFS的数据存储系统,用于存储结构化数据,Google的分布式计算模型是由这三大组件组成的。而后Yahoo的工程师Doug Cutting和Mike Cafarella根据Google三篇技术论文中的相关原理在2005年合作开发了分布式计算系统Hadoop,并使其成为了Apache基金会的开源项目[3]。 Hadoop使用MapReduce作为分布式计算框架,这也是Hadoop平台中处理分析数据的主要部分,根据GFS开发HDFS分布式文件系统,用于管理平台中的大量数据,根据BigTable开发了HBase数据存储系统。Hadoop对海量数据的处理能力促使其他互联网公司也开始了基于Google分布式框架的研究,由UC Berkeley AMP lab开源的分布式并行计算框架Spark,是基于Hadoop MapReduce进行一些架构上的优化,两者间最大的差距是Spark的数据可以保存在内存,不需要如MapReduce一般访问HDFS(硬盘),所以更适用于一些需要迭代的MapReduce算法。Strom是由Backtype团队开发的分布式计算系统,也是有Twitter主推的Apache基金会的孵化项目,它与Hadoop和Spark的区别在于Strom不需要进行数据的收集和存储工作,而是通过网络实时直接接受数据并实时处理数据,然后直接传回结果,这是因为Strom在Hadoop的基础上提供了实时运算的特性,所以可以实时的处理大数据流。目前,Hadoop,Spark和Strom是最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Strom常用于在线的实时的大数据处理[4]。
1.2 项目背景
本项目来源于江苏科技有限公司。数据的价值高低是由数据处理分析的能力强弱决定的,若不对数据进行处理分析,大数据也仅仅是一堆成本高而收益为零的库存。国内流行的大数据技术目前仍然停留在数据收集、整理、存储和简单报表等几个初级阶段,这也是由于企业普遍在数据库、数据仓库、商业智能等领域的基础薄弱。而与此同时国内相对强势的互联网企业、电信运营商、电信设备供应商已经开始调整产业布局,以争取在互联网应用服务中取得大数据制高点[5]。
文中涉及的项目是构建一个基于Hadoop集群的大数据基础平台,这个大数据平台的应用场景之一为电网的用电采集系统进行数据分析。这个系统设计的整体结构如下:
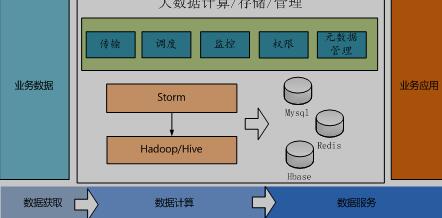
图1.1 系统设计整体结构
由图可知,这个系统主要的功能是对大数据的计算、存储和管理,包括的功能模块有数据传输、调度、系统监控、用户权限管理、元数据管理。从逻辑上来说整个系统可以分为一下三个部分: Kafka大数据平台的数据传输模块开发设计(2):http://www.youerw.com/jisuanji/lunwen_30013.html